第1章 问答环节
为什么选择Python
- 软件质量, 可重用性,可维护性 (EIBTI,明了胜于晦涩)
- 提高开发者的效率, 使用更少的代码完成更多的工作
- 程序的可移植性
- 标准库的支持,Python通过自行开发的库或是第三方的应用支持来进行扩展。
- 组件集成,可以与众多的编程语言互相调用(C, C++, java, SOAP等)
- 享受编程的乐趣
Python的缺点
- 与C和C++类的编译语言相比,Python的执行速度还不够快。
Python将源代码的语言转为字节码的形式,而不是底层的二进制形式
Python可以做什么?
- 系统编程, 利用Python本身自带的标准库进行维护操作系统
- 用户图形接口, 利用TKinter内置的接口 Tk GUI API,可以快速的开发windows, linux, Mac OS的窗口程序
- Internet脚本, 不论是服务器端还是客户端都能应用,利用众多的Web开发工具包,可以迅速的搭建网站
- 组件集成
- 数据库编程,Python提供了对所有主流关系数据库系统的接口
- 快速原型,通过Python做系统原型,再移植到C或C++这样的编译语言上。
- 数值计算和科学计算编程
- 游戏,图像,人工智能,XML,机器人等
第2章 Python如何运行程序
Python解释器
编写的Python代码必须在解释器中运行,解释器是一种让其他程序运行起来的程序。
程序执行
程序员视角
Python的扩展名一般为 *.py *, 利用任何一种文本编辑器就可以创建。在CMD(windows)中, 输入
1 | python script0.py |
就可以运行之前输入的代码结果
Python视角
运行Python脚本的过程
代码 → 字节码(.pyc编译过的源代码) → 虚拟机(PVM)
如何运行程序
交互提示模式下编写代码
在各系统的终端,Shell, CMD中直接进行交互编程
输入python后,输入以下代码
1 | >>> print("Hello world!") |
为什么使用交互提示模式
交互提示是体验语言和测试编写中的程序文件的好地方。
- 代码立即执行
- 不明代码实验
使用交互模式的注意事项
- 只能够输入Python命令
- 在文件中打印语句是必须的
- 在交互模式下不需要缩进(自动缩进)
- 留意提示符的变化
- 在交互提示模式中,用一个空行来结束复合语句。
- 交互模式一次运行一条语句
- 交互模式不能保存代码
通过文件执行第一段脚本
使用任何一种文本编辑器(vi, Notepad, IDLE),创建一个script1.py的文件,并输入以下代码(注意保存时的文件扩展名)
1 | # A first Python script |
在终端中,我们使用 Python script1.py来运行程序
我们也可以使用 Python script1.py 》 saveit.txt 来保存运行的结果
值得注意的还有一点,在UNIX和Linux上使用Python,第一行是特定的,要使用 #!/usr/local/bin/python
windows中直接双击执行py文件
虽然双击后自动执行,但一般情况都是一闪而过,需要保留画面的话,需在代码中加入一条input()函数
1 | # A first Python script |
导入模块和重载
每一个扩展名为.py的Python 源代码文件就是一个模块。其他的文件可以通过导入一个模块读取这个模块的内容
导入方法
1 | import script1.py |
导入后会自动执行一次源代码,再次导入时,不执行源代码,如果想再次运行文件的话,使用reload函数
1 | from imp import reload #Python3.0后,reload被移动到imp标准库模块中 |
模块的特性: 属性
模块中的变量一般被称为属性
如果你的工作目录不是Python默认的工作目录,你需要使用chdir
先创建一个模块文件myfile.py
1 | title = "The Meaning of Life" |
导入
1 | >>> import os |
模块和命名空间
Python程序需要导入多个模块,通过import连接起来,每个模块文件是一个独立完备的变量包,即一个命名空间
命名空间可以避免变量同名的冲突
使用exec运行模块文件
1 | >>> exec(open('script1.py').read()) |
exec和import有着同样的效果,但exec不是导入,而是复制代码到exec的地方,对于当前正在使用的变量有潜在默认覆盖的可能。
第4章 Python对象类型
为什么使用内置类型
- 内置对象使程序更容易编写。不需要所有的功能都自己编写
- 内置对象是扩展组件。
- 内置对象往往比定制的数据结构更有效率。
- 内置对象是语言的标准的一部分。
(总结)内置对象是亲生的,自己编写的肯定比不过亲生的快
Python的核心数据类型
| 对象类型 | 例子 常量/创建 |
|---|---|
| 数字 | 1234, 3.1415, 3+4j, Decimal, Fraction |
| 字符串 | ‘spam’, “guido’s”, b’a\xolc’ |
| 列表 | [1,[2,’three’],4] |
| 字典 | {‘food’:’spam’, ‘taste’:’yum’} |
| 元组 | (1, ‘spam’, 4, ‘u’) |
| 文件 | myfile=open(‘eggs’, ‘r’) |
| 集合 | set(‘abc’),{‘a’, ‘b’, ‘c’} |
| 其他类型 | 类型,none, 布尔型 |
| 变成单元类型 | 函数,模块, 类 |
| 与现实相关的类型 | 编译的代码堆栈跟踪 |
数字
数字类型包含,整数,浮点数,以及更为少见的类型
Python提供了一些数学模块
math模块包括更高级的数学工具,如函数,而random模块可以作为随机数字的生成器和随机选择器
1 | >>> import math |
字符串
字符串是用来记录文本信息的,是字符的集合。字符串是单个字符的字符串的序列
序列的操作
1 | >>> S = 'Spam' |
字符串的分片操作
1 | >>> S[1:3] |
字符串可以通过 + 号合并也可以通过 * 号 重复
1 | >>> S + ' is Boy' |
字符串的不可变性
字符串在Python中具有不可变性,在创建之后不能就地改变。但是可以通过建立一个新的字符串并以同一个变量名对其进行赋值。
1 | >>> S[0] = 'z' #直接修改字符串出错 |
字符串的特定方法
find方法
find方法可以对字符串进行查找操作。1
2
3
4
5
6
7
8
9
10
11>>> S.find('pa')
1
>>> S.replace('pa', 'XYZ')
'zXYZm'
>>> s
Traceback (most recent call last):
File "<pyshell#31>", line 1, in <module>
s
NameError: name 's' is not defined
>>> S
'zpam'replace方法
replace方法可以对字符串进行替换。但不修改原始字符串split()方法
可以根据指定的字符对字符串进行分割,返回列表1
2
3>>> line = "aaa,bbb,ccc,dddddd"
>>> line.split(',')
['aaa', 'bbb', 'ccc', 'dddddd']upper方法
将字符串转大写1
2
3>>> line2= line.split(',')
>>> line2[1].upper()
'BBB'isalpha方法
检测字符串是否只由字母组成。1
2>>> line2[3].isalpha()
True
内置方法帮助
如果想了解对象的相应方法及更多细节,可以调用内置的dir函数,将会返回一个列表,其中包含了对象的所有属性。
1 | >>> dir(line2) |
一般以双下划线开头并结尾的变量名是用来表示Python实现细节的命名模式。而这个列表中没有下划线的属性是字符串对象能够调用的方法。
具体的函数使用方法,可以使用help函数
1 | >>> help(line2.sort) |
之后会有正则表达式的相关说明
列表
列表对象是Python语言中提供的最通用的序列。列表无固定大小
序列操作
1 | >>> L = [123, 'spam', 1.23] |
列表的特定类型的操作
1 | >>> L.append('NI') |
append方法,可以扩充列表的大小并在列表的尾部插入一项
pop方法,移除给定偏移量的一项,从而让列表减小。
reverse方法,对列表进行翻转。
sort方法,队列表进行排序,但只针对相同对象。
边界检查
因为Python不会自动增大列表,所以写代码的时候注意列表的边界检查
列表嵌套
列表可以以任意的组合对其进行嵌套,可以实现矩阵(多维数组)
列表解析
列表解析源自于集合的概念。它是一种通过对序列中的每一项运行一个表达式来创建一个新列表的方法,每次一个,从左至右。
字典
Python中的字典是一种映射。映射是一个其他对象的集合,但是他们是通过键而不是相对位置来存储的。实际上,映射并没有任何可靠的从左至右的顺序。他们简单地将键映射到值。字典具有可变性,可以随需求增大或减小。
字典的映射操作
作为常量编写时,字典编写在大括号中。并包含一系列的“减:值”对。
1 | D={'food': 'Spam', 'quantity': 4, 'color': 'pink'} |
重访嵌套
键的排序:for循环
因为字典不是序列,他们并不包含任何可靠的从左至右的顺序。
1 | >>> D = {'a' : 1, 'c' : 3, 'b' : 2} |
在最新的Python版本中我们可以使用sorted调用结果。
1 | >>> for key in sorted(D): |
for 循环是遍历一个序列中的所有元素并按照顺序对每一个元素运行一些代码的简单并有效的一种方法。
使用if测试不存在的键
1 | >>> D |
通过if就能简单的判断一个字典中是否含有该键,当然还有其他方法。
元组
元组对象其实就是一个不可以改变的列表。元组是序列,但是它具有不可变性, 和字符串类似。从语法上讲,他们编写在圆括号中,支持任意类型,任意嵌套以及常见的序列操作
1 | >>> T = (1,2,3,4) |
元组的真正不同之处就是,一经创建就不能改变,包括大小。
文件
文件对象是Python代码对电脑上外部文件的主要接口。
第5章 Python的数字
Python的数字类型
数字并不是一个真正的对象类型,而是一组类似类型的分类。
- 整数和浮点数
- 复数
- 固定精度的十进制数
- 有理分数
- 集合
- 布尔类型
- 无穷的整数精度
- 各种数字内置函数和模块
数字常量
- 整数和浮点数常量
- Python3.0 将一般整数和长整数合二为一了。省略了Python2末尾的l或L
- 十六进制数, 八进制和二进制常量 十六进制以0x或0X开头, 八进制常量以0o或0O开头,二进制常量以0b或0B开头。
- 复数, 实部加虚部
内置数学工具和扩展
- 表达式操作符 +,-,,/,>>, *, &等
- 内置数学函数 pow, abs, round, int, hex, bin等
- 公共模块 random, math等
第6章 动态类型
Python属于动态类型
缺少类型声明语句
Python的变量类型是由运行过程中自动决定的。而不是通过代码声明。
变量,对象和引用
- 变量创建, 当代吗第一次给它赋值的时候就创建了它。
- 变量类型, 变量永远不会有任何的他关联的类型信息或约束。类型的概念存在于对象中。
- 变量使用, 当变量出现在表达式中,它会马上被当前引用的对象所替代。
对象的垃圾收集
在Python中,每当一个变量名被赋予了一个新的对象,之前的那个对象占用的空间就会被回收。这种自动回收对象空间的技术叫做垃圾收集。
共享引用
多变量名引用同一对象,在Python中被称为共享引用
1 | >>> a =3 |
很多人会问,改变了a的值,为什么b不发生变化,这其实还停留在一般编程的思考层面上。
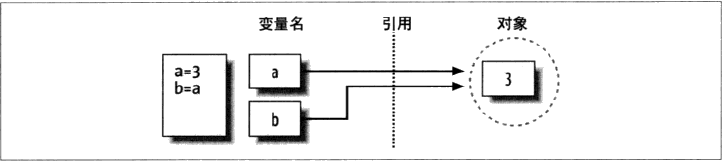
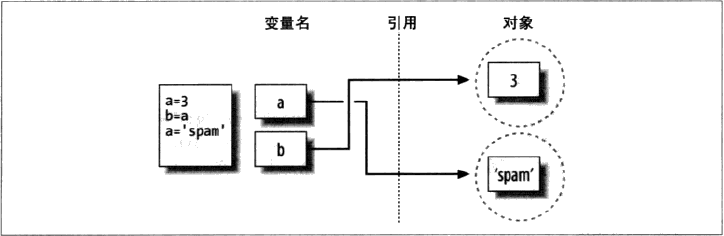
可以看到这里的a其实已经不指向对象数字3,而是指向了对象字符串‘spam’, 在Python中,变量总是一个指向对象的指针,而不是可改变的内存区域的标签,给一个变量赋一个新的值,并不是替换了原始的对象,而是让这个变量去引用完全不同的一个对象。
共享引用和在原处修改
1 | >>> L1 = [1,2,3] |
这里这种对列表的修改,就造成了共享引用同时发生了变化,因为在这里L1和L2指向的是相同的对象。修改列表里的元素,并不能产生新的对象。而是直接修改了元对象导致。
如果不想出现这样的情况就需要进行一些变化
1 | >>> L2 = L1[:] |
通过L2 = L1[:] 创建一个对象列表的副本,这样就不会造成一同变化的情况了
而字典或集合应该使用X.copy()方法调用。
共享引用和相等
在Python程序中有两种不同的方法来检查对象是否相等。
1 | >>> L = [1,2,3] |
== 操作符, 测试两个被引用的对象是否有相同的值。
is 操作符, 是检查对象的同一性(其他语言的===),是更严格的相等测试。
1 | >>> L = [1,2,3] |
不过这里需要注意的是,整数和字符串会被缓存复用,所以不适合严格比较
1 | >>> X = 42 |
Python的字符串
字符串常量
使用方法
- 单引号: ‘spa”m’
- 双引号: “spa’m”
- 三引号: ‘’’…spam…’’’, “””…spam…”””
- 转义字符: “s\tp\na\om”
- Raw字符串:r”C:\new\test.spm”
单双引号字符串是一样的
在Python字符串中,单引号和双引号字符是可以互换的。
用转义序列代表特殊字节
转义序列让我们能够在字符串中嵌入不容易通过键盘输入的字节
使用‘\’添加指定的字符,形成如换行,制表符,等特殊字节
字符串反斜杠字符
| 转义 | 意义 |
|---|---|
| \newline | 忽视(连续) |
| \\ | 反斜杠 |
| ' | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 倒退 |
| \f | 换页 |
| \n | 换行 |
| \r | 返回 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \N{id} | Unicode数据库ID |
| \uhhhh | Unicode 16位的十六进制值 |
| \Uhhhhhhhh | Unicode 32位的十六进制值 |
| \xhh | 十六进制值 |
| \ooo | 八进制值 |
| \0 | Null |
| \other | 不转义 |
raw字符串抑制转义
在使用转义字符的时候,其实会遇到这样或那样的问题,为了抑制转义,raw字符串诞生
一般字母r(大写或小写)出现在字符串的第一个引号的前面,它将关闭转义机制
1 | myfile = open(r'C:\new\text.dat', 'w') |
三重引号编写多行字符串块
三重引号也可以叫做块字符串,这是一种对编写多行文本数据来说很便捷的语法
1 | >>> mantra = """Always look |
实际应用中的字符串
基本操作
1 | >>> len("abc") #len函数可以返回字符串的长度 |